Performance testing RabbitMQ Streams
This post first appeared on the LShift web site.
RabbitMQ Streams is our data streams management system that allows arbitrary routing, transforming, and merging of messages. We used a “quick and dirty” test framework during development to check there were no major performance issues, but we needed to improve on this to test the real configurations used by the BBC Feeds Hub.
The top level functionality of the system under test (SUT) is:
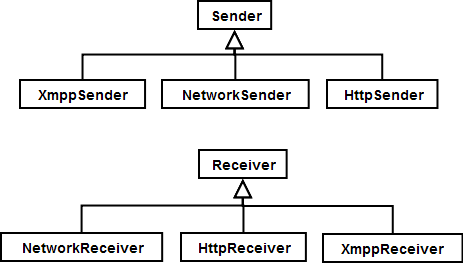
- messages can enter the SUT via any number of ingress points, and using a number of protocols such as raw socket, HTTP and XMPP
- messages pass through a number of processors where they can be transformed or routed to the next processor
- messages can exit the SUT via any number of egress points, again, using a number of protocols
We need a set of senders and receivers to be able to simulate a number of agents inserting and receiving the messages.
The receivers need to be able to calculate the time taken to deliver each message and therefore need the time the message was sent. There are two options for this:
- include a timestamp with each message
- have the sender log the timestamp in a store accessible to the receiver
Ideally, there should be no message modifications made so that real data can be used for testing and there is no corruption due to modifications getting caught up in any transforms. This rules out the first option but the second option ends up running into the same problem.
The receiver needs a way to look up the sent timestamp for a given message. The logical way would be to use a hash of each message as the key but this can fail because messages may not be unique and they can also be legitimately modified by the SUT. The only way to find the message again is to insert a unique ID. After studying the configs and messages, we found that content prefixed or appended to a message would be unaltered by any transforms and would not affect any other processing steps. A mechanism for test authors to define how to insert data into each test data set using regular expressions was added.
Given that message modification was necessary, it still leaves the decision of which option to go with. Using a shared store is extra development overhead, but it does give added flexibility if later on a better way of identifying messages is introduced. For example, a future version of RabbitMQ Streams may acknowledge inbound messages with a unique ID that is kept with the message during processing, and then sent out of the egress gateway as a HTTP header or other mechanism suitable for the protocol.
The requirements for the shared message store are to:
- hold a timestamp for each sent message keyed by a unique ID
- support concurrent access by multiple senders and receivers, possibly from different machines if the tests are run in a distributed environment
- perform an insert and successful lookup in less time than it takes the SUT to process a message under the specified test configurations. Failure to do so will result in a backlog of messages to process that will causes problems for long running soak tests
memcached is a lightweight object caching system that is accessible via multiple clients over a network, and can be scaled up to run efficiently over a cluster, so in theory it should always be possible to make its performance exceed the SUT.
This is how it fits in with the design so far:
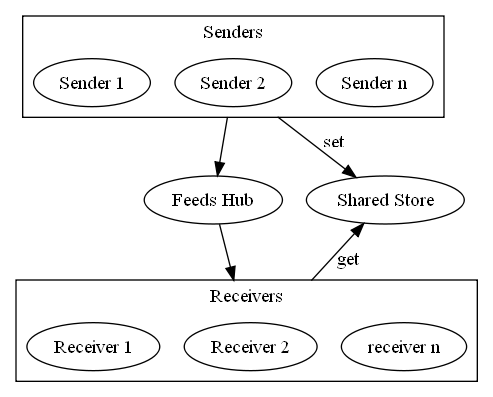
This covers the test harness from the perspective of the test domain, but it will also need infrastructure for configuring and executing tests, and collecting results. The original performance test harness used The Grinder framework. As well as a solid framework, it allows test scripts to be written in Jython which gives the test author the flexibility to utilise any mix of Python and Java, and therefore leverage various APIs to support the protocols that could be used. It is also a distributed framework so that tests can be run from a number of machines to simulate large scale use.
Typical use of The Grinder involves invoking a process and seeing how long it takes to complete. This will not work for this scenario because the initial invocation is an asynchronous process. The Grinder is used slightly differently for the senders and receivers:
- Senders; The Grinder is used to configure each sender, and to set message insertion parameters such as the rate, size, number of threads / runs etc. The Grinder will automatically record how long each test invocation takes, and therefore each insertion. This is not a required measurement but useful for spotting problems in the ingress gateways.
- Receivers; The Grinder is used to configure each receiver. However, message processing is event driven rather than under control of the test framework. In order to maximise the accuracy of the results, the first action for each received message is to record the message and received time, and place it on a queue. Each Grinder test invocation pulls a message and timestamp off the queue ready to calculate the delivery time. This method of working does not offer any benefit other than allowing us to use an existing framework for the configuration, recording and control.
Details of the design can be found in the package, or directly on GitHub. The test harness has worked well, and has been used to successfully demonstrate the performance requirement of Feeds Hub.
Going forward, I would like to move the test harness to use The Grinder in a more idiosyncratic way. For example:
- The Grinder invokes a test
- The sender inserts the message into the SUT and blocks
- The SUT process the message and passes it to a receiver
- The receiver records the received time in the shared message store
- The sender periodically polls the message store to see if original message has been delivered
- The sender retrieves the delivered time from the message store, and overrides The Grinder test time
This would be a cleaner design but would require some additional configuration and control for the receivers. The main drawback however is that senders block until the message is delivered so may not be available to send more messages to achieve a given traffic pattern. This could be overcome by coordinating several senders but again, would require additional work to do so.